- Published on
From Text to Brilliance: A Brief Overview of GPT-3 Paper
- Authors

- Name
- Amir Lavasani
- @AmirMLavasani
Recent advancements in NLP leverage pre-training and fine-tuning, yet these methods require extensive task-specific data. Human-like few-shot learning remains a challenge. We present GPT-3, a language model with 175 billion parameters, demonstrating superior few-shot performance without fine-tuning. GPT-3 excels across diverse tasks, including translation, question-answering, and creative tasks. Challenges and methodological issues arise on specific datasets. GPT-3 generates news articles that mimic human writing, prompting societal implications.
Introduction
The trend in NLP involves pre-trained language representations used in flexible, task-agnostic ways. This has evolved from single-layer representations through multi-layer RNNs to fine-tuned recurrent or transformer models, resulting in substantial progress on challenging NLP tasks. However, the requirement for task-specific datasets and fine-tuning remains a significant constraint.
The limitations of current language models stem from the need for vast labeled datasets per task, constraints in fine-tuning on narrow task distributions, and an inability to replicate human adaptability. Human capability in performing tasks with minimal examples highlights a gap in current NLP techniques, affecting both conceptual understanding and practical efficiency.
Meta-learning offers a potential solution to challenges by training models with diverse skills and pattern recognition abilities, enabling rapid adaptation at inference. Recent in-context learning methods condition models using natural language instructions and demonstrations to perform tasks. However, current results lag behind fine-tuning, indicating the need for substantial enhancements to make meta-learning practically effective.
The trend of expanding transformer language model capacities has yielded improvements in text synthesis and NLP tasks, suggesting potential gains for in-context learning abilities. To investigate, a 175 billion parameter autoregressive language model, GPT-3, is trained. GPT-3 is evaluated on diverse NLP datasets and novel tasks, exploring its in-context learning prowess across various conditions - few-shot, one-shot, and zero-shot learning.
The study examines GPT-3's performance in few-shot learning for various NLP tasks. The model's proficiency improves with contextual examples and size. In some cases, GPT-3 rivals or surpasses fine-tuned models. It excels in rapid adaption tasks, like arithmetic, novel word usage, and unscrambling words. However, it struggles with specific tasks like ANLI and certain reading comprehension datasets. The study also assesses data contamination effects and investigates smaller models' performance relative to GPT-3.

Presents aggregate performance for 42 accuracy-based benchmarks. It indicates that as the model size increases, zero-shot performance improves steadily. Notably, few-shot performance experiences more rapid enhancement, showcasing the heightened proficiency of larger models in in-context learning
Approach
The paper introduces four distinct learning settings: Fine-Tuning (FT), Few-Shot (FS), One-Shot (1S), and Zero-Shot (0S), for evaluating GPT-3's performance. These settings span a spectrum of task-specific data reliance. FT involves weight updates on a specific dataset, FS and 1S allow a few demonstrations or one demonstration plus a task description, and 0S involves only a task description. While FT excels in benchmarks, it requires extensive task data. FS reduces task-specific data needs but lags behind fine-tuned models. 1S mirrors human task communication, and 0S resembles maximum convenience and challenge, sometimes even exceeding human comprehension. Each setting offers unique advantages and challenges for evaluating language model capabilities.
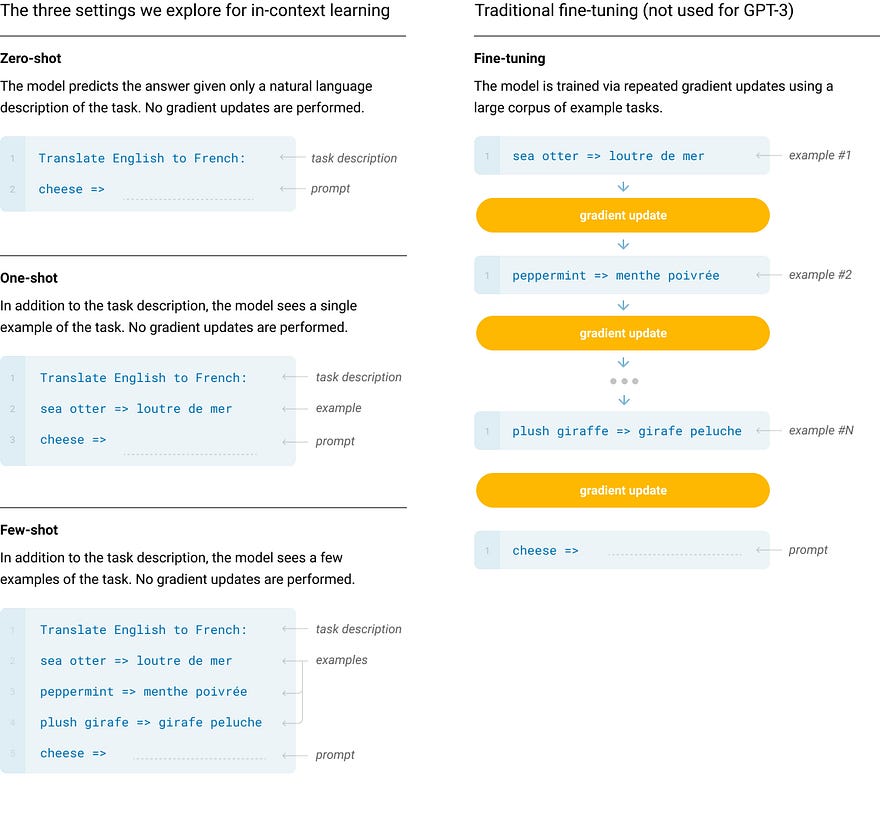
Contrasts traditional fine-tuning with zero-shot, one-shot, and few-shot methods for language model tasks. The study focuses on the latter three methods.
Model and Architectures
The study employs the same model and architecture as GPT-2 with specific modifications, including locally banded sparse attention patterns. Eight models of varying sizes from 125 million to 175 billion parameters are trained to explore the relationship between model size and performance. The table displays key architectural details of these models, and efficient GPU partitioning strategies are employed.
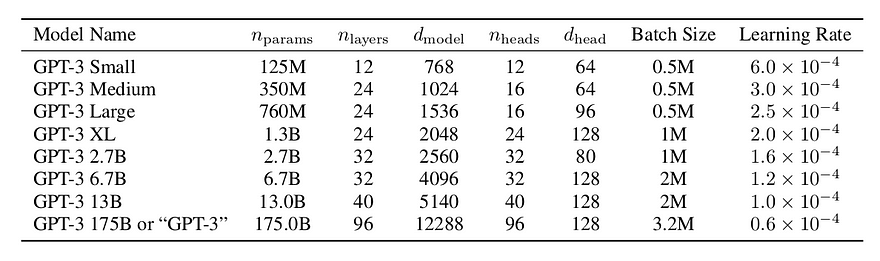
Sizes, architectures, and learning hyper-parameters (batch size in tokens and learning rate) of the models which we trained. All models were trained for a total of 300 billion tokens.
Training Dataset
The expansion of language model datasets, like the Common Crawl dataset, has been significant, reaching trillions of words. While such large datasets are suitable for training large models, data quality issues exist. Steps were taken to enhance dataset quality by: (1) obtaining and filtering Common Crawl data based on high-quality reference corpora, (2) implementing fuzzy deduplication at the document level, and (3) adding reputable reference corpora to augment the training mix.
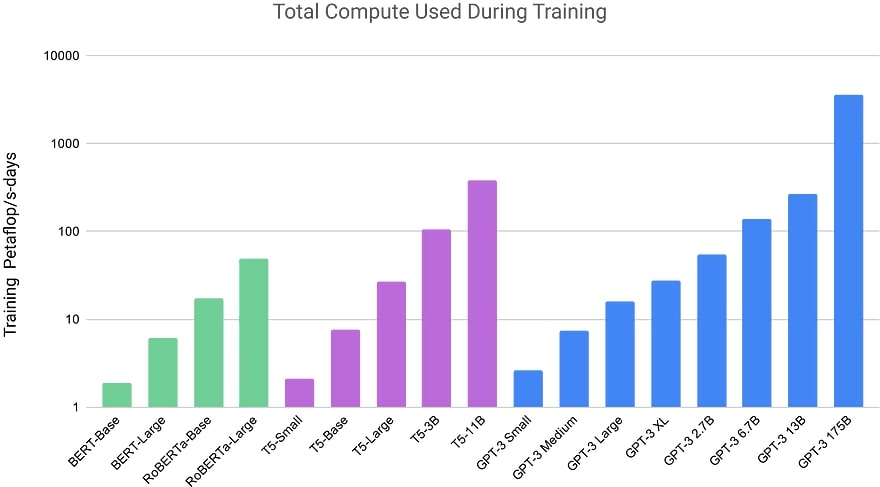
The study employed significantly larger models trained on fewer tokens compared to typical practices. For instance, despite GPT-3 3B being nearly 10 times larger than RoBERTa-Large (355M params), both models required around 50 petaflop/s-days of compute during pre-training.
The training dataset mixture used in the study includes CommonCrawl data from 2016 to 2019, covering 45TB of compressed plaintext before filtering and 570GB after filtering, equivalent to about 400 billion byte-pair-encoded tokens. Datasets were sampled based on perceived quality, with higher-quality datasets sampled more frequently. Efforts were made to prevent contamination of downstream tasks by removing overlaps with development and test sets of benchmarks; however, some overlaps remained due to a filtering bug.
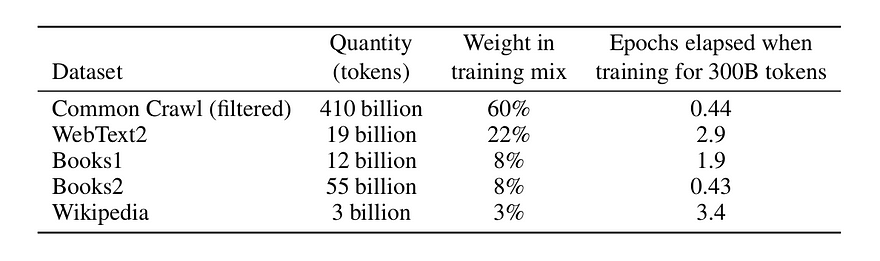
The training datasets for GPT-3 were selected using a non-proportional distribution strategy, where the fraction of examples from each dataset during training doesn't strictly reflect the dataset's size. This approach aimed to ensure that certain quality datasets are seen multiple times during training, while others are encountered less frequently.
Training Process
Training of larger language models involves adapting the batch size and learning rate. Larger models can handle bigger batch sizes with smaller learning rates. The gradient noise scale is monitored to determine the optimal batch size. Model parallelism is used in matrix multiplication and layer-wise parallelism to prevent memory constraints. V100 GPUs on a high-bandwidth Microsoft cluster are used for training.
The evaluation of GPT-3's performance involves few-shot learning on various tasks. K examples are drawn from each task's training set and used as conditioning for evaluation. Model context window (nctx) is set at 2048 tokens, accommodating around 10 to 100 examples. The evaluation includes multiple-choice tasks, binary classification, and free-form completions. Final results are reported on public test sets or, when unavailable, on development sets. Submission to private test servers is done for selected datasets, primarily with 200B few-shot results, while other results are reported on the development set.
Results
Training curves for 8 models, including 175 billion parameter GPT-3 and smaller ones, are shown in the next figure. Language modeling performance follows a power-law trend, indicating consistent improvement. Evaluation of these models covers a broad range of datasets, categorized into various tasks. These include traditional language modeling tasks, question answering, translation, Winograd Schema-like tasks, commonsense reasoning, reading comprehension, SuperGLUE benchmark, and more. Evaluation is conducted in few-shot, one-shot, and zero-shot settings for various tasks.
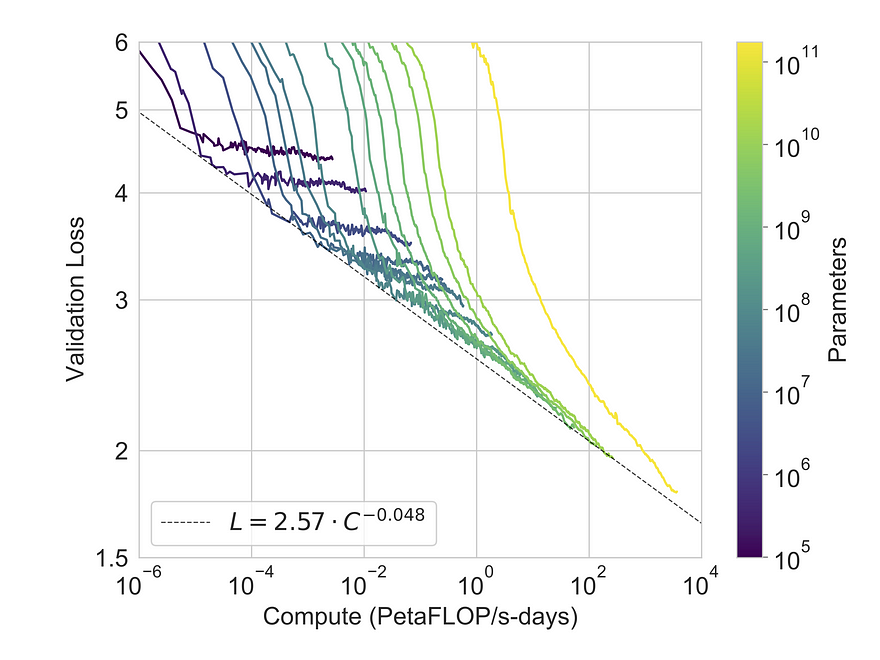
The relationship between performance, measured through cross-entropy validation loss, and training compute exhibits a smooth power-law trend. This trend, seen in previous work, extends over two more orders of magnitude with minor deviations from the expected curve.
Hope you enjoyed 👏
Here is the original paper if you want to dive deeper.