- Published on
Beyond Speech Recognition: OpenAI's Whisper
- Authors

- Name
- Amir Lavasani
- @AmirMLavasani
In the dynamic field of speech recognition, OpenAI introduces Whisper, a pioneering system poised to revolutionize the way we perceive voice technology. This article delves into the extraordinary capabilities of Whisper as presented in OpenAI's paper, "Robust Speech Recognition via Large-Scale Weak Supervision."
- Introduction
- Approach
- Model
- Multitask Format
- Training Details
- Experiments
- Zero-shot Evaluation
- Evaluation Metrics
- English Speech Recognition
- Multi-lingual Speech Recognition
- Translation
- Language Identification
- Comparison with Human Performance
- Model and Dataset Scaling
- Related Work
- Scaling Speech Recognition
- Multitask Learning
- Robustness
- Conclusion
Introduction
Historically, speech recognition heavily relied on supervised pre-training, demanding extensive human data labeling. However, the landscape has shifted with the advent of unsupervised pre-training methods, exemplified by Wav2Vec 2.0. These approaches, which leverage extensive unlabeled speech data, have transformed the scale and efficiency of speech recognition.
Whisper takes this transformation further. Trained on an astounding 680,000 hours of multilingual and multitask data, it excels on standard benchmarks without laborious fine-tuning. The results are remarkable, with Whisper's models nearing human-level accuracy and robustness.
Implications are profound. Whisper signifies a future where speech recognition systems work seamlessly across diverse environments without the need for extensive supervised fine-tuning.
This journey explores Whisper's technological marvel, its unprecedented data scale, multilingual and multitask abilities, and the potential it holds for robust speech recognition. Join us as we delve into the heart of Whisper, a transformative force redefining speech recognition boundaries. Whisper is a testament to technology's boundless potential.
Approach
In the pursuit of crafting a transformative speech recognition system, OpenAI's Whisper takes a unique approach, standing on the shoulders of recent trends in machine learning. Central to this approach is data processing, where Whisper distinguishes itself through its minimalist methodology.
Whisper's approach to speech recognition is marked by its minimalist data processing methods. Unlike traditional approaches, it trains models to predict raw transcripts without extensive standardization. This simplifies the speech recognition pipeline.
The dataset is constructed from a diverse range of audio paired with transcripts found on the internet. To enhance transcript quality, automated filtering methods are employed.
To avoid machine-generated transcripts, heuristics are used. An audio language detector ensures spoken and transcript languages match. Fuzzy de-duplication minimizes repetition and auto-generated content.
Audio is segmented into 30-second pieces, paired with corresponding transcript sections. An additional filtering pass is conducted, identifying and removing low-quality data sources.
Transcript-level de-duplication prevents contamination. These streamlined processes form the core of Whisper's remarkable speech recognition capabilities.
Model
OpenAI's approach focuses on harnessing the capabilities of large-scale supervised pre-training for speech recognition. In this pursuit, they employ an off-the-shelf architecture, opting for an encoder-decoder Transformer, a well-validated and scalable structure. All audio data is re-sampled to 16,000 Hz, and 80-channel log-magnitude Mel spectrogram representations are computed on 25-millisecond windows with a 10-millisecond stride. Feature normalization scales the input globally between -1 and 1, with an approximate zero mean across the pre-training dataset.
The encoder handles this input representation and consists of a small stem with two convolution layers, utilizing the GELU activation function. Sinusoidal position embeddings are added to the output of the stem, followed by the application of transformer blocks. The transformer employs pre-activation residual blocks, and a final layer normalization is applied to the encoder output. The decoder uses learned position embeddings and tied input-output token representations, with the encoder and decoder sharing the same width and number of transformer blocks. The model architecture is summarized in Figure 1.
The same byte-level Byte-Pair Encoding (BPE) text tokenizer used in GPT-2 is employed for the English-only models. For multilingual models, the vocabulary is refit to avoid fragmentation while maintaining the same size.
Multitask Format
In speech recognition, multiple components like voice activity detection, speaker diarization, and text normalization accompany word prediction, creating complexity. OpenAI simplifies this by aiming for a single model to handle the full speech processing pipeline.
They employ a streamlined format for task specification, using input tokens to guide the decoder. This format enables language prediction, task definition (transcription or translation), and timestamp predictions. It simplifies complex tasks by allowing a single model to address diverse requirements. Refer to Figure 1 for a visual representation of this format and the training setup.
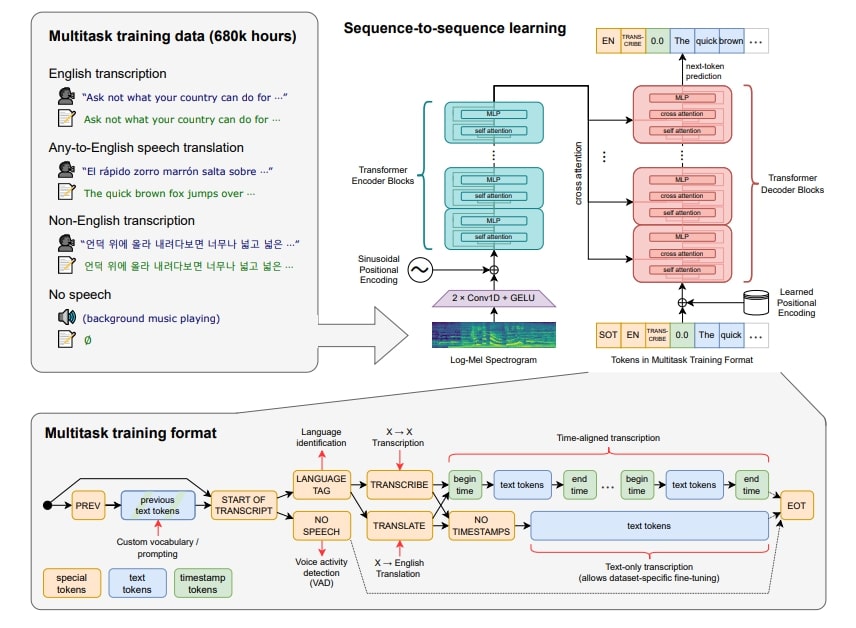
Whisper's sequence-to-sequence Transformer model. It's trained for various speech tasks like recognition, translation, identification, and activity detection. (Image from the paper)
Training Details
OpenAI investigates Whisper's scalability with various model sizes (see the following table). Training employs data parallelism, FP16, dynamic loss scaling, and activation checkpointing. AdamW and gradient norm clipping are used with a linear learning rate decay. The batch size is 256 segments, and training comprises 220 updates, balancing between two and three passes over the dataset. Overfitting concerns are minimal, and no data augmentation or regularization is applied, relying on dataset diversity for generalization and robustness. For detailed training hyperparameters, see original paper's Appendix F.
During initial development, models exhibited a tendency to incorrectly predict speaker names due to their prevalence in training transcripts. To address this, models are briefly fine-tuned on transcripts without speaker annotations, eliminating this behavior.
| row | Model | Layers | Width | Heads | Parameters |
|---|---|---|---|---|---|
| 1 | Tiny | 4 | 384 | 6 | 39M |
| 2 | Base | 6 | 512 | 8 | 74M |
| 3 | Small | 12 | 768 | 12 | 244M |
| 4 | Medium | 24 | 1024 | 16 | 769M |
| 5 | Large | 32 | 1280 | 20 | 1550M |
Architecture details of the Whisper model family. (Table from the paper)
Experiments
Zero-shot Evaluation
Whisper's primary aim is to create a robust speech processing system capable of performing well in diverse scenarios without the need for dataset-specific fine-tuning. To put Whisper to the ultimate test, the evaluation follows a zero-shot approach. This means that for each dataset, Whisper refrains from using any of the training data during evaluation, providing insight into its broad generalization capabilities.
Evaluation Metrics
In speech recognition, systems are commonly assessed using the Word Error Rate (WER), which penalizes even minor differences, such as formatting variations. This poses a unique challenge for zero-shot models like Whisper.
Whisper addresses this challenge by applying text standardization before calculating WER. This process reduces WER significantly, with up to a 50% improvement for some datasets. However, it's important to note the potential risk of overfitting to Whisper's transcription style.
To support the community, Whisper provides its text normalizer code, facilitating comparisons and the study of speech recognition system performance in out-of-distribution contexts.
English Speech Recognition
Whisper aims to match human-like speech recognition, testing its abilities against the vast LibriSpeech dataset. Historically, human-level performance was achieved, but recent models fell short when applied to other scenarios.
The gap between human and machine capabilities arises from differing training methods. Humans learn without specific supervision, assessing their out-of-distribution adaptability. Machines typically train on data closely aligned with their evaluation distribution, gauging their in-distribution adaptability.
Whisper models, trained broadly and evaluated in a zero-shot manner, show promise in better mirroring human capabilities. They outperform standard models on various datasets, even the smaller Whisper model with only 39 million parameters. This suggests the importance of zero-shot and out-of-distribution evaluations, avoiding overestimations of machine capabilities.
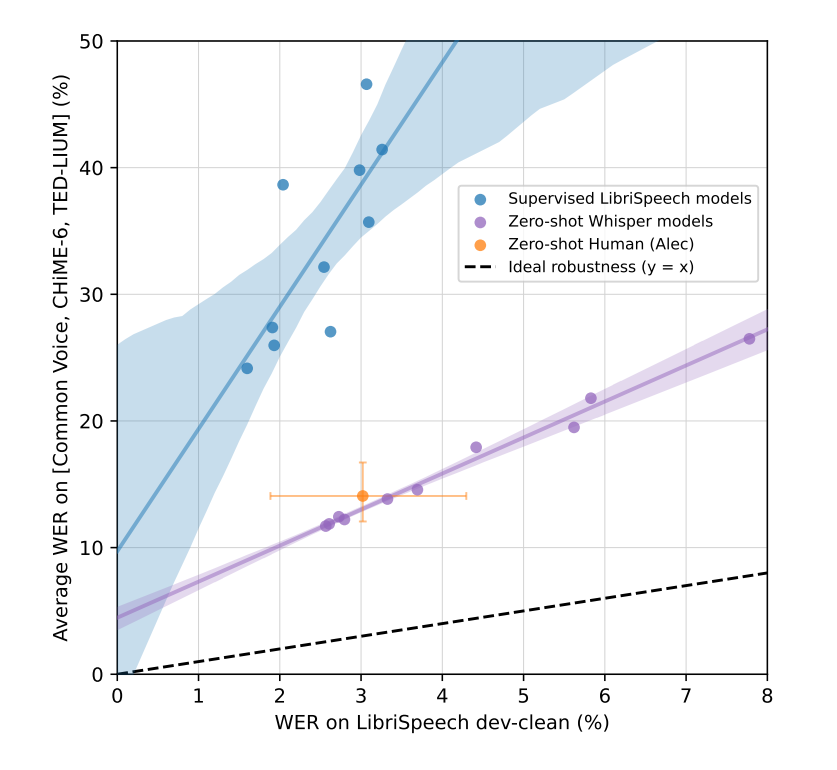
Zero-shot Whisper models close the gap to human robustness. (Image from the paper)
Multi-lingual Speech Recognition
Whisper delves into multilingual speech recognition. It excels in Multilingual LibriSpeech but lags behind in VoxPopuli due to data differences.
Whisper's multilingual prowess spans 75 languages, and examined on the Fleurs dataset. The authors find a strong correlation between training data and performance. Some unique-script and distant languages perform worse, possibly due to transfer difficulties, tokenization issues, or data variations.
| row | Dataset | wav2vec 2.0 (Large -no LM) | Whisper (Large V2) | RER (%) |
|---|---|---|---|---|
| 1 | LibriSpeech Clean | 2.7 | 2.7 | 0 |
| 2 | Artie | 24.5 | 6.2 | 74.7 |
| 3 | Common Voice | 29.9 | 9.0 | 69.9 |
| 4 | Fleurs En | 14.6 | 4.4 | 69.9 |
| 5 | Tedlium | 10.5 | 4.0 | 61.9 |
| 6 | CHiME6 | 65.8 | 25.5 | 61.2 |
| 7 | VoxPopuli En | 17.9 | 7.3 | 59.2 |
| 8 | CORAAL | 35.6 | 16.2 | 54.5 |
| 9 | AMI IHM | 37.0 | 16.9 | 54.3 |
| 10 | Switchboard | 28.3 | 13.8 | 51.2 |
| 11 | CallHome | 34.8 | 17.6 | 49.4 |
| 12 | WSJ | 7.7 | 3.9 | 49.4 |
| 13 | AMI SDM1 | 67.6 | 36.4 | 46.2 |
| 14 | LibriSpeech Other | 6.2 | 5.2 | 16.1 |
| 15 | Average | 29.3 | 12.8 | 55.2 |
Detailed comparison of effective robustness across various datasets. (Table from the paper)
Translation
Whisper's translation capabilities were put to the test on the CoVoST2 X→en dataset. It achieved a groundbreaking 29.1 BLEU score, zero-shot, outperforming previous top performers. This success is attributed to Whisper's extensive pre-training data, providing 68,000 hours of X→en translation, far surpassing CoVoST2's 861 hours. It excelled, especially for low-resource languages but didn't surpass Maestro and mSLAM for high-resource languages.
In a broader analysis, Fleurs, typically used for speech recognition, was used for translation tasks. The correlation between translation training data and zero-shot BLEU scores was observed, albeit with less certainty due to noisier data. For example, despite having 9,000 hours of translation data, Welsh (CY) scored only 13 BLEU due to misclassified English audio.
Language Identification
Whisper's zero-shot language identification performance falls short compared to supervised systems, with a 13.6% difference. However, it's essential to note that Whisper is at a disadvantage due to a lack of training data for 20 out of the 102 languages in Fleurs.
Comparison with Human Performance
To gauge Whisper's closeness to human performance, 25 recordings from the Kincaid46 dataset were analyzed. Results show that Whisper's English ASR performance is remarkably close to human-level accuracy, although not flawless.
Model and Dataset Scaling
Weakly supervised training offers the potential to use massive datasets, but this data can be noisy. The concern is that model performance may plateau at the dataset's inherent quality, possibly below human-level. Also, as capacity and compute increase, models might overfit and struggle with out-of-distribution data.
The paper examined this by studying Whisper's zero-shot generalization with varying model sizes. In most cases, performance improved with larger models, except for English speech recognition, possibly due to nearing human-level performance.
The paper then explored the importance of dataset size. Whisper's 680,000-hour dataset is massive. The authors trained medium-sized models on subsamples of the data ranging from 0.5% to 8% and compared their performance. Larger datasets consistently improved performance, but the rate of improvement varied across tasks. For English speech recognition, improvements slowed down after 54,000 hours, suggesting diminishing returns. This trend extended to other tasks, raising questions about the optimal balance between data size and model capacity.
Further analysis is needed to understand the scaling laws for speech recognition and to determine if more extensive training and larger models can enhance performance.
| row | Dataset Size (Hours) | English WER (↓) | Multilingual WER (↓) | X→En BLEU (↑) |
|---|---|---|---|---|
| 1 | 3,405 | 30.5 | 92.4 | 0.2 |
| 2 | 6,811 | 19.6 | 72.7 | 1.7 |
| 3 | 13,621 | 14.4 | 56.6 | 7.9 |
| 4 | 27243 | 12.3 | 45.0 | 13.9 |
| 5 | 54,486 | 10.9 | 36.4 | 19.2 |
| 6 | 681,070 | 9.9 | 29.2 | 24.8 |
Performance improves with increasing dataset size (Table from the paper)
Related Work
Scaling Speech Recognition
Scaling in speech recognition involves using larger models, increased computational resources, and bigger datasets. Deep learning enhanced speech recognition with larger models and GPU acceleration (Mohamed et al., 2009). Using larger datasets, especially demonstrated by the 2,000-hour Switchboard dataset, significantly improved performance (Seide et al., 2011). Weakly supervised learning expanded datasets by over 1,000 hours (Liao et al., 2013). This trend continued with models like Deep Speech 2 (Amodei et al., 2015).
Multitask Learning
Multitask learning has been influential in various domains. In speech recognition, it involves training models to handle multiple tasks simultaneously. Multilingual models have been studied for over a decade (Schultz & Kirchhoff, 2006). The text-to-text framework, popularized by transformer models, simplifies multi-task learning (McCann et al., 2018; Radford et al., 2019; Raffel et al., 2020). Large-scale multitask models have been developed for multiple languages (Pratap et al., 2020a) and explored joint training for text and speech language tasks (Wang et al., 2020c; Bapna et al., 2022).
Robustness
Model generalization and robustness have been extensively studied in machine learning. Models often struggle with generalizing between datasets (Torralba & Efros, 2011). High performance on standard test sets doesn't guarantee robustness (Lake et al., 2017; Alcorn et al., 2019; Recht et al., 2019). Multi-domain training enhances model robustness, a trend seen across various fields (Hendrycks et al., 2020; Radford et al., 2021).
Conclusion
Whisper's experiments underscore the importance of scaling weakly supervised pre-training in speech recognition research. Whisper achieved remarkable results without relying on self-supervision and self-training, which are common in large-scale speech recognition projects. Instead, the paper demonstrated the effectiveness of training on a diverse supervised dataset and focusing on zero-shot transfer to enhance the robustness of a speech recognition system.
Hope you enjoyed 👏
Here is the original paper if you want to dive deeper. 🧐