- Published on
Transformer Model: A Review of the Iconic Attention Paper
- Authors

- Name
- Amir Lavasani
- @AmirMLavasani
In machine learning and deep learning, there's a fundamental concept that plays a pivotal role in a variety of applications, particularly in Natural Language Processing (NLP). This concept is called "attention."
- Introduction
- The Need for Attention
- Limitations of Traditional Models
- The Birth of the Transformer Model
- The Transformer Model
- The Essence of the Transformer
- Components of the Transformer
- Benefits of the Transformer
- How the Transformer Differs
- Self-Attention Mechanism
- The Basics of Self-Attention
- Multi-Head Self-Attention
- The Power of Multiple Heads
- Positional Encoding
- Training the Transformer
- Results and Impact
- Breakthrough in Machine Translation
- Conclusion
Introduction
In machine learning and deep learning, there's a fundamental concept that plays a pivotal role in a variety of applications, particularly in Natural Language Processing (NLP). This concept is called "attention." The ability to focus on specific parts of data while ignoring others is a critical aspect of many tasks, from translation to sentiment analysis.
However, traditional sequence-to-sequence models, such as Recurrent Neural Networks (RNNs) and Long Short-Term Memory networks (LSTMs), had their limitations when it came to handling long-range dependencies in sequences. Google, in their groundbreaking paper "Attention is all you need," introduced a novel architecture that revolutionized the way we approach these problems.
The Need for Attention
In the world of Natural Language Processing and machine learning, understanding the context and relationships between words in a sequence is paramount. Traditional sequence-to-sequence models, such as Recurrent Neural Networks (RNNs) and Long Short-Term Memory networks (LSTMs), were the pioneers in tackling these problems. However, they exhibited several limitations that called for a more efficient and effective solution.
Limitations of Traditional Models
Sequential Computation: RNNs and LSTMs process data sequentially. They read the input data one element at a time and maintain a hidden state that carries information from the past. While this approach worked for many tasks, it proved inefficient for tasks that required capturing long-range dependencies.
Difficulty in Parallelization: The sequential nature of these models made parallelization challenging. In the era of GPUs and TPUs, where parallel processing is a key to faster training, these models fell short.
Vanishing and Exploding Gradients: RNNs and LSTMs were notorious for the vanishing and exploding gradient problems, which hindered their ability to learn and transfer knowledge over long sequences.
Limited Context: These models had difficulty considering the entire context of a sentence or document, as their memory was constrained by their hidden state.
The Birth of the Transformer Model
It was in the face of these challenges that Google introduced the Transformer model in their paper "Attention is all you need." The Transformer was a breath of fresh air in the machine learning community.
This revolutionary model relied solely on attention mechanisms, eliminating the need for recurrent connections. It promised to capture long-range dependencies efficiently and in parallel. The self-attention mechanism in the Transformer allowed it to weigh the importance of different words in a sentence dynamically, enabling it to focus on the relevant context for each word.
The Transformer not only addressed the limitations of traditional models but also paved the way for faster and more effective training on modern hardware.
With this understanding of why there was a need for a new approach, let's dive deeper into the core of the Transformer model in the next section.
The Transformer Model
At the heart of Google's seminal paper lies the revolutionary Transformer model. This section is dedicated to unraveling the core architecture of the Transformer and understanding its transformative impact on the field of machine learning.
The Essence of the Transformer
The Transformer model is a departure from traditional sequence-to-sequence models. It introduces a new architecture that leverages attention mechanisms to handle sequences effectively. The key idea is to focus on self-attention, allowing the model to weigh the importance of different words in a sentence dynamically.
Components of the Transformer
Encoder-Decoder Architecture: The Transformer model consists of both an encoder and a decoder. The encoder processes the input sequence, while the decoder generates the output sequence. Each of them is composed of multiple layers.
Multi-Head Self-Attention: A pivotal component in the Transformer is the multi-head self-attention mechanism. Instead of having a single attention mechanism, the model employs multiple attention heads, enabling it to focus on different parts of the input sequence simultaneously.
Positional Encoding: One challenge the Transformer addresses is that it doesn't have an inherent sense of the order of words in a sequence. To tackle this, positional encoding is added to the input embeddings. This encoding provides information about the position of each word in the sequence, ensuring the model can capture the sequential context.
Feed-Forward Networks: In addition to self-attention layers, the Transformer employs feed-forward neural networks to process the information at each position within the sequence.
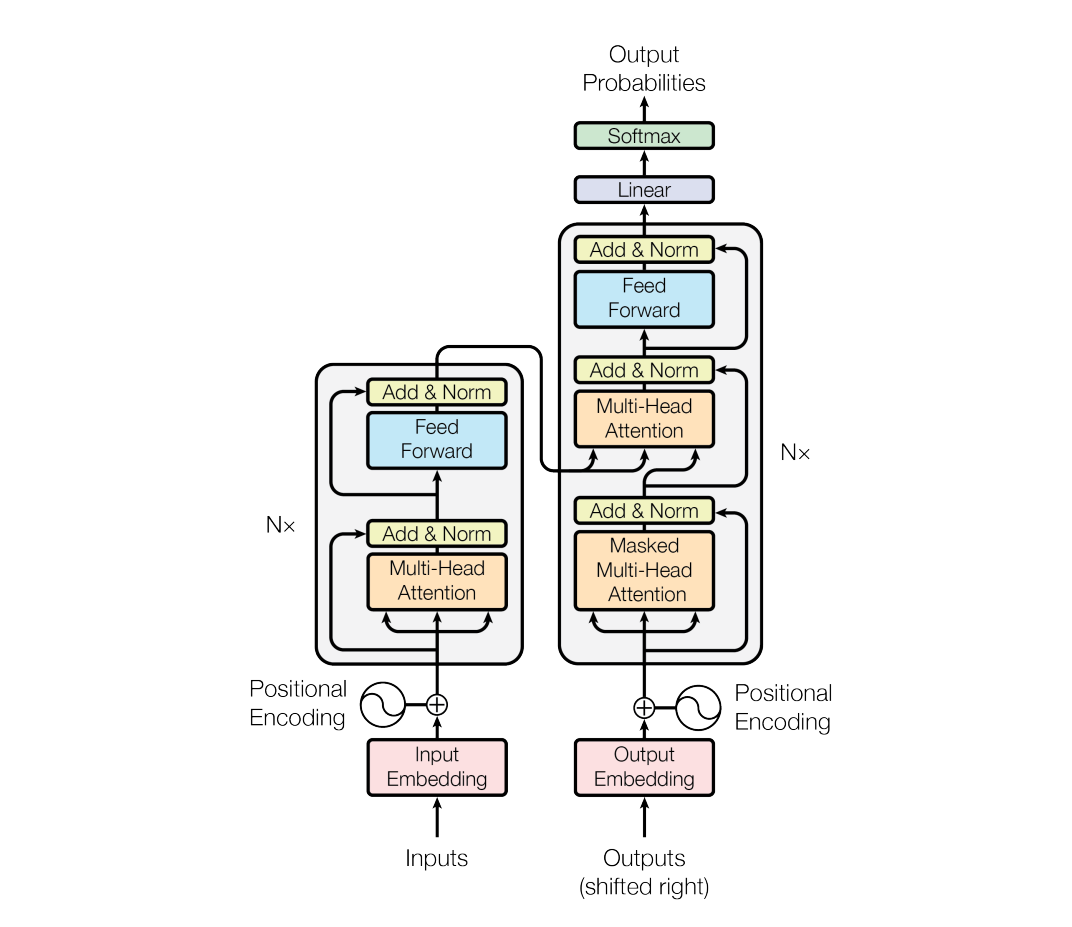
The Transformer follows this overall architecture using stacked self-attention and point-wise, fully connected layers for both the encoder and decoder, shown in the left and right halves respectively (Image from the paper)
Benefits of the Transformer
The Transformer's unique architecture brings several benefits:
Parallelization: Unlike traditional models, the Transformer can process all elements in a sequence in parallel, making it highly efficient on modern hardware.
Long-Range Dependencies: The self-attention mechanism allows the model to capture long-range dependencies effectively, making it ideal for tasks like machine translation where understanding the entire context is essential.
Scalability: The Transformer model scales well with the amount of data and computational resources, which is a significant advantage in large-scale applications.
Interpretable Attention: The attention weights generated by the Transformer model are interpretable, providing insights into why the model makes specific predictions.
How the Transformer Differs
The Transformer's reliance on self-attention mechanisms and its ability to handle sequences in parallel sets it apart from traditional models like RNNs and LSTMs. While these traditional models were sequential and struggled with vanishing and exploding gradients, the Transformer made training faster and more efficient.
The removal of recurrent connections in favor of self-attention and feed-forward layers is a paradigm shift that significantly improved the modeling of sequences, making it a game-changer in NLP and beyond.
As we've explored the core of the Transformer model, we'll delve even deeper into the self-attention mechanism in the next section.
Self-Attention Mechanism
To understand the inner workings of the Transformer model, one must grasp the concept of the self-attention mechanism. This ingenious mechanism is at the heart of the model's success, enabling it to weigh the importance of different words in a sentence dynamically. It's like giving each word the ability to decide which other words it should pay attention to when making predictions, a game-changer in the world of NLP.
The Basics of Self-Attention
At its core, self-attention is a mechanism that computes a weighted sum of all words in a sentence, where the weight assigned to each word depends on how relevant it is to the current word in focus. Here's how it works:
Input Embeddings: Before self-attention, the input sentence is represented as embeddings, with each word converted into a high-dimensional vector.
Query, Key, and Value: In self-attention, each word in the sentence is associated with three vectors: Query, Key, and Value. These vectors are learned during training.
Scoring the Relevance: To compute the attention score between two words, their Query and Key vectors are used. The score reflects how relevant the Key word is to the Query word.
Attention Weights: The attention scores are then scaled using a scaling factor (often the square root of the dimension of the Key vectors) and passed through a softmax function. This results in attention weights that sum to 1, indicating the importance of each word in the context of the Query word.
Weighted Sum: Finally, the attention weights are used to take a weighted sum of the Value vectors. This weighted sum represents the information from other words that is most relevant to the Query word.
Multi-Head Self-Attention
The Transformer model takes self-attention to the next level by employing multiple attention heads. Each head learns different patterns and dependencies within the text. This not only enhances the model's ability to capture diverse relationships between words but also makes it more robust and interpretable.
In essence, the self-attention mechanism is the magic that empowers the Transformer model to understand the context of a sentence effectively. It's a breakthrough that paved the way for the model's success in various NLP tasks, from translation to text generation.
The Power of Multiple Heads
The self-attention mechanism, as we've discussed in the previous section, allows a word to attend to other words in a sentence dynamically. However, it turns out that a single attention mechanism may not be sufficient to capture the diverse and complex relationships between words.
Multi-Head Attention addresses this limitation by using multiple sets of Query, Key, and Value transformations. Each set is responsible for learning different patterns and dependencies within the text. These different heads effectively divide and conquer the complex relationships present in the input data. Here's how it works:
Multiple Sets of Parameters: In Multi-Head Attention, instead of having just one set of Query, Key, and Value transformations, we have multiple sets. These sets of parameters are learned during training.
Parallel Processing: Each set of parameters processes the input data in parallel. This means that the model can simultaneously focus on different parts of the input, capturing diverse relationships.
Concatenation and Linear Transformation: After each set of parameters generates its own set of attention-weighted values, the results are concatenated and linearly transformed. This creates a comprehensive representation of the input data that captures various patterns.
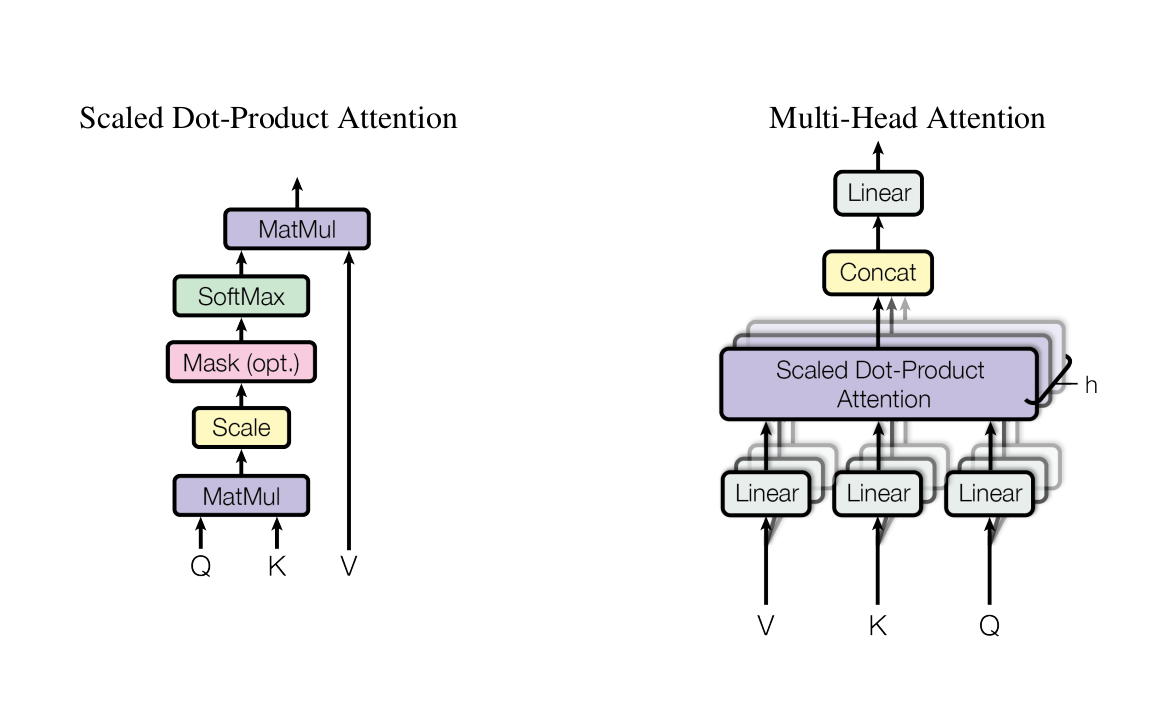
(left) Scaled Dot-Product Attention. (right) Multi-Head Attention consists of several attention layers running in parallel. (Image from the paper)
Positional Encoding
In the absence of recurrence and convolution in the model, the paper introduces the concept of "positional encodings" to incorporate information about the relative or absolute positions of tokens within a sequence. These positional encodings are added to the input embeddings at the base of the encoder and decoder stacks and share the same dimension (dmodel) as the embeddings, allowing their summation.
The paper presents two options for positional encodings, including learned and fixed methods. In this work, sine and cosine functions of varying frequencies are utilized:
Here, pos denotes the position in the sequence, and i represents the dimension. Each dimension of the positional encoding corresponds to a sinusoidal function, with wavelengths forming a geometric progression. The selected approach allows the model to effectively attend to relative positions. Importantly, it is noted that the model can extrapolate to longer sequence lengths than those encountered during training.
The paper highlights that both learned and sinusoidal positional encodings were experimented with, and they produced nearly identical results. However, the sinusoidal version was chosen for its potential to facilitate sequence length extrapolation. This component, positional encoding, is fundamental to the model's ability to understand the sequence's order, a critical aspect in natural language processing tasks.
Training the Transformer
The Transformer's training, as outlined in the original paper, is a critical factor in its success. This section covers key training details, including data, hardware, optimization, and regularization.
The model trained on the WMT 2014 English-German dataset (4.5 million sentence pairs) and the larger English-French dataset (36 million sentences). Batching was done based on sequence length, with each batch containing approximately 25,000 source and 25,000 target tokens.
Training utilized a single machine with 8 NVIDIA P100 GPUs. Base models were trained for 100,000 steps (12 hours), and larger models for 300,000 steps (3.5 days).
The Adam optimizer was used with specific hyperparameters, including learning rate adjustments during training.
Regularization techniques included residual dropout and label smoothing. Residual dropout applied to sub-layers and positional encodings, while label smoothing improved accuracy and BLEU score.
These meticulous training details are essential for the Transformer's effectiveness in understanding and generating natural language text.
Results and Impact
The results obtained from the Transformer model, as outlined in the original paper, showcase its exceptional performance and far-reaching impact on natural language processing.
Breakthrough in Machine Translation
In the domain of machine translation, the Transformer model achieved remarkable results. On the challenging WMT 2014 English-to-German translation task, the "big" Transformer model (Transformer (big)) presented in Table 2 achieved a groundbreaking BLEU score of 28.4. This outperformed all previously reported models, including ensembles, by a substantial margin of more than 2.0 BLEU points. Notably, this established a new state-of-the-art BLEU score. The model's configuration, detailed in the bottom line of Table 3, required 3.5 days of training on 8 P100 GPUs. Even the base model surpassed previous models and ensembles in performance, achieving this feat at a significantly reduced training cost compared to competitive models.
On the equally challenging WMT 2014 English-to-French translation task, the "big" Transformer model exhibited a remarkable BLEU score of 41.0. This surpasses all previously published single models while maintaining a training cost of less than 1/4 of the previous state-of-the-art model. It's important to note that for the English-to-French translation, the Transformer (big) model used a dropout rate of _ = 0.1*, as opposed to _0.3*.
| row | Model | EN-DE BLEU (↑) | EN-FR BLEU (↑) |
|---|---|---|---|
| 1 | ByteNet | 23.75 | - |
| 2 | Deep-Att + PosUnk | - | 39.2 |
| 3 | GNMT + RL | 24.6 | 39.92 |
| 4 | ConvS2S | 25.16 | 40.46 |
| 5 | MoE | 26.03 | 40.56 |
| 6 | Deep-Att + PosUnk Ensemble | - | 40.4 |
| 7 | GNMT + RL Ensemble | 26.30 | 41.16 |
| 8 | ConvS2S Ensemble | 26.36 | 41.29 |
| 9 | Transformer (base model) | 27.3 | 38.1 |
| 9 | Transformer (big) | 28.4 | 41.8 |
The Transformer achieves better BLEU scores than previous state-of-the-art models on the English-to-German and English-to-French (Table from the paper)
Conclusion
The advent of the Transformer model, as showcased by the results and profound impact outlined in this paper, represents a watershed moment in the realm of natural language processing. The Transformer's exceptional performance in machine translation, its ability to outperform previous models by substantial margins, and its cost-effectiveness in training have reshaped the landscape of language understanding and generation.
The model's adaptability, epitomized by its capacity for generalization and transfer learning, has reverberated not only through academia but also across industries and practical applications. Its influence extends to the development of voice assistants, chatbots, and a myriad of language-related technologies.
The Transformer model sets a high standard, capturing intricate linguistic dependencies and inspiring future advancements in NLP. It serves as a beacon of progress and innovation, promising a rich future in artificial intelligence and human-computer interaction.
Hope you enjoyed 👏
Here is the original paper if you want to dive deeper. 🧐