- Published on
LoRA: A Revolution in Fine-Tuning
- Authors

- Name
- Amir Lavasani
- @AmirMLavasani
Large Language Models (LLMs) are drastically reshaping how we interact with computers, growing in size and capability every day.
However, as these models expand, fine-tuning them for specific tasks becomes increasingly costly and nearly impractical.
- Before we Start
- What is LoRA?
- The Math Behind LoRA
- Drawbacks of Existing Methods
- Key Advantages of LoRA
- Practical Benefits and Constraints
- Conclusion
Before we Start
Let's start with some definitions. A low-rank approximation of a matrix tries to get close to the original matrix but with a lower complexity. Matrix rank indicates its complexity;
A lower-rank matrix simplifies computations, making matrix multiplications more efficient. Low-rank decomposition is the process of effectively approximating a matrix A by creating lower-rank versions of A.
Singular Value Decomposition (SVD) stands as a common approach for this.
What is LoRA?
LoRA, Low-Rank Adaptation, is a fine-tuning method.
It optimizes smaller matrices instead of recalculating gradients for most parameters, making it computationally efficient.
LoRA presents a way to freeze the pre-trained model's parameters and introduces trainable decomposition matrices into each layer, significantly minimizing the parameters that undergo fine-tuning.
Take GPT-3 175B, for example; LoRA can reduce the number of trainable parameters by 10,000 times and the GPU memory requirement by 3 times.
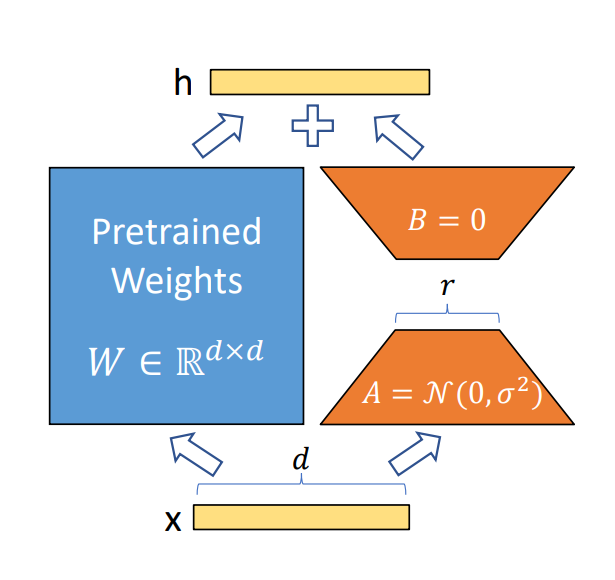
LoRA reparametrization. LoRA only trains A and B. (Image from the paper)
The Math Behind LoRA
Let's say we have a pre-trained autoregressive language model parametrized by .
Now we want to adapt the language model to conditional text generation tasks such as summarization, machine reading comprehension, question answering, or natural language to SQL.
Each of these tasks is represented by a training dataset of context-target pairs:
where both and are sequences of tokens.
For example in summarization, is the content of an article and its summary.
During full fine-tuning, the model weights are initialized to and we update the weights to + repeatedly by gradient decent. However One of the main drawbacks is that for each downstream task, we learn a different set of parameters whose dimension equals .
Fine-tuning, storing, deploying, and managing lots of fine-tuned models with the new parameters with the same dimension as the original model is challenging if at all feasible on independent researchers' hardware.
LoRA introduces a parameter-efficient approach, where the task-specific parameter increment is further encoded by a much smaller-sized set of parameters with .
For the encoding of LoRA proposes to use a low-rank representation that is both compute- and memory-efficient.
Drawbacks of Existing Methods
- Adapter Layers Introduce Latency: Strategies like adapter layers aim to minimize parameters, but they often bring about inference delays. Even with a small parameter count, the sequential processing nature of adapter layers increases latency, becoming noticeable in scenarios like running GPT-2 on a single GPU.
- Challenges with Prompt Optimization: Methods like prefix tuning face optimization difficulties, impacting performance non-monotonically with trainable parameters. Moreover, allocating sequence length for adaptation could compromise downstream task processing, affecting prompt optimization efficiency.
Key Advantages of LoRA
Parameter Efficiency: LoRA constrains weight updates via a low-rank matrix decomposition, minimizing trainable parameters while maintaining model expressiveness.
Generalization of Fine-Tuning: Unlike traditional fine-tuning, LoRA doesn't require full-rank gradient updates, enabling a substantial reduction in the number of trainable parameters without sacrificing model expressiveness.
Latency-Free Deployment: LoRA's design ensures no added inference latency during deployment, allowing seamless task-switching without additional computational overhead.
Practical Benefits and Constraints
Memory Efficiency: LoRA significantly reduces memory usage, allowing for a 2/3 reduction in VRAM consumption during training, leading to smaller checkpoints and streamlined model deployment.
Task Flexibility: LoRA enables effortless task-switching with minimal computational cost, facilitating the creation of customized models for various applications.
Performance Enhancement: Training with LoRA demonstrates a 25% speedup compared to full fine-tuning, optimizing computational resources.
Limitations: Challenges exist in batching inputs for different tasks in a single forward pass, potentially impacting latency in specific scenarios.
Conclusion
LoRA presents a pivotal solution by significantly reducing computational demands and memory requirements for adapting large-scale language models. Its innovative approach of low-rank parametrization offers a promising pathway to efficient and effective model adaptation, promising vast potential across various applications in natural language processing.
Here is the link to the Paper, and the GitHub implementation.
Hope you enjoyed 👏 Happy fine-tunning 🦾